Autoresearch Growth Loops Need Reality Checks
LLM judges are useful for generating pressure, but they drift when they judge themselves. The better loop ships variants, waits for real behavior, and starts the next round from evidence.
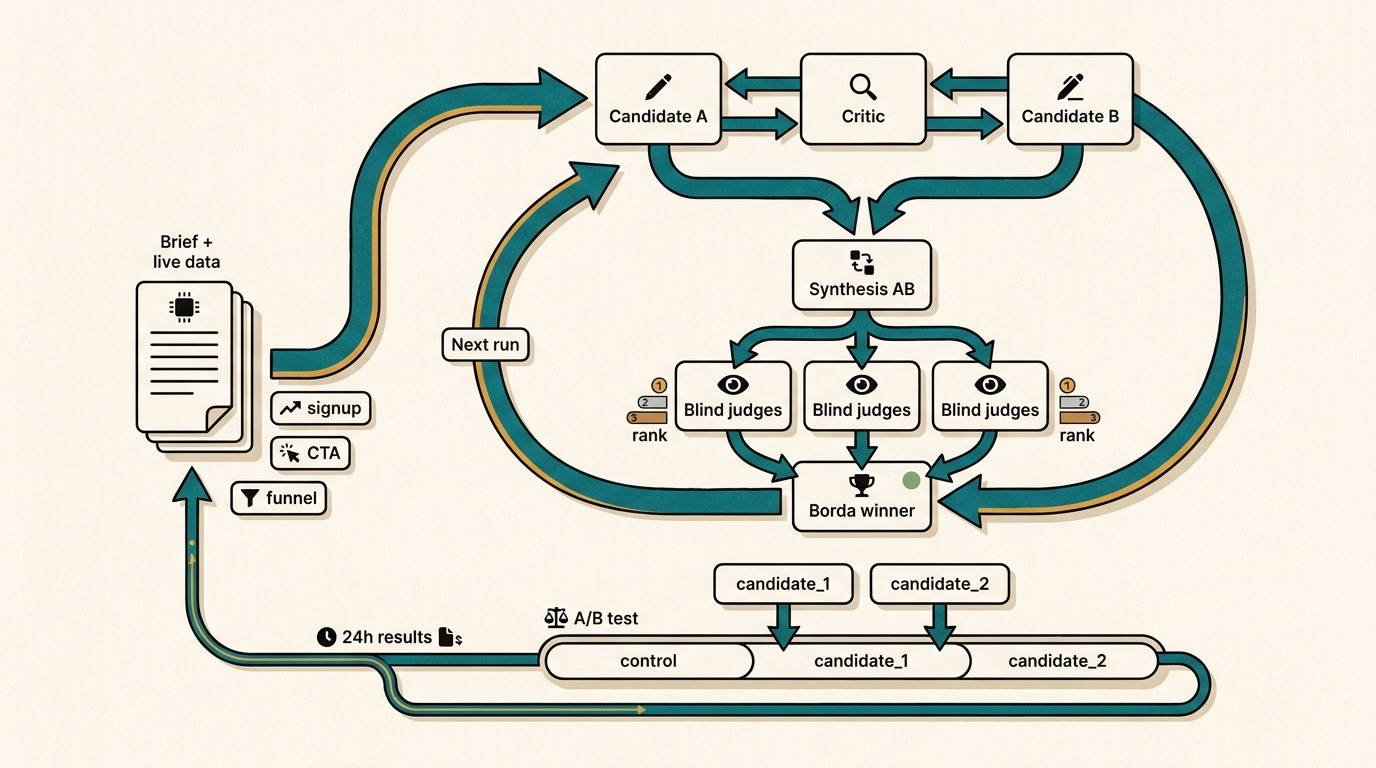
We forked Andrej Karpathy’s autoresearch because growth loops need a second judge: users.
The repo is here: Agent-Analytics/autoresearch-growth
The problem with adapting autoresearch to growth is not generation. The problem is self-judging.
You can run a candidate, critic, revision, synthesis, and blind-judge loop many times and still converge on copy that LLM judges like more than users do.
Shoutout to Shan Holmberg’s AutoReason thread on X for pushing the marketing version of this pattern. The shape is useful: one agent writes, another criticizes, another rewrites, a synthesizer combines, and blind judges pick with Borda scoring.
That is much better than asking one model for “better marketing copy.”
But this reply points at the real risk: LLM judges have biases. They reward length, formality, surface polish, and things that sound smart.
Three biased judges do not become the market.
LLM Judges Have Biases
The loop is useful because it creates pressure. It finds weak claims. It catches generic copy. It can produce two strong experiment candidates faster than a human staring at a blank page.
But the LLM panel should be treated as a filter, not proof. Proof comes later:
- did
signupmove? - did
cta_clickmove? - did bounce get worse?
- did scroll depth improve?
- did signup quality hold?
- did the page still say something true?
That is where the loop should slow down.
That is the value: the loop stops judging itself.
A Loop On Top Of The Loop
The growth version is a loop on top of the loop.
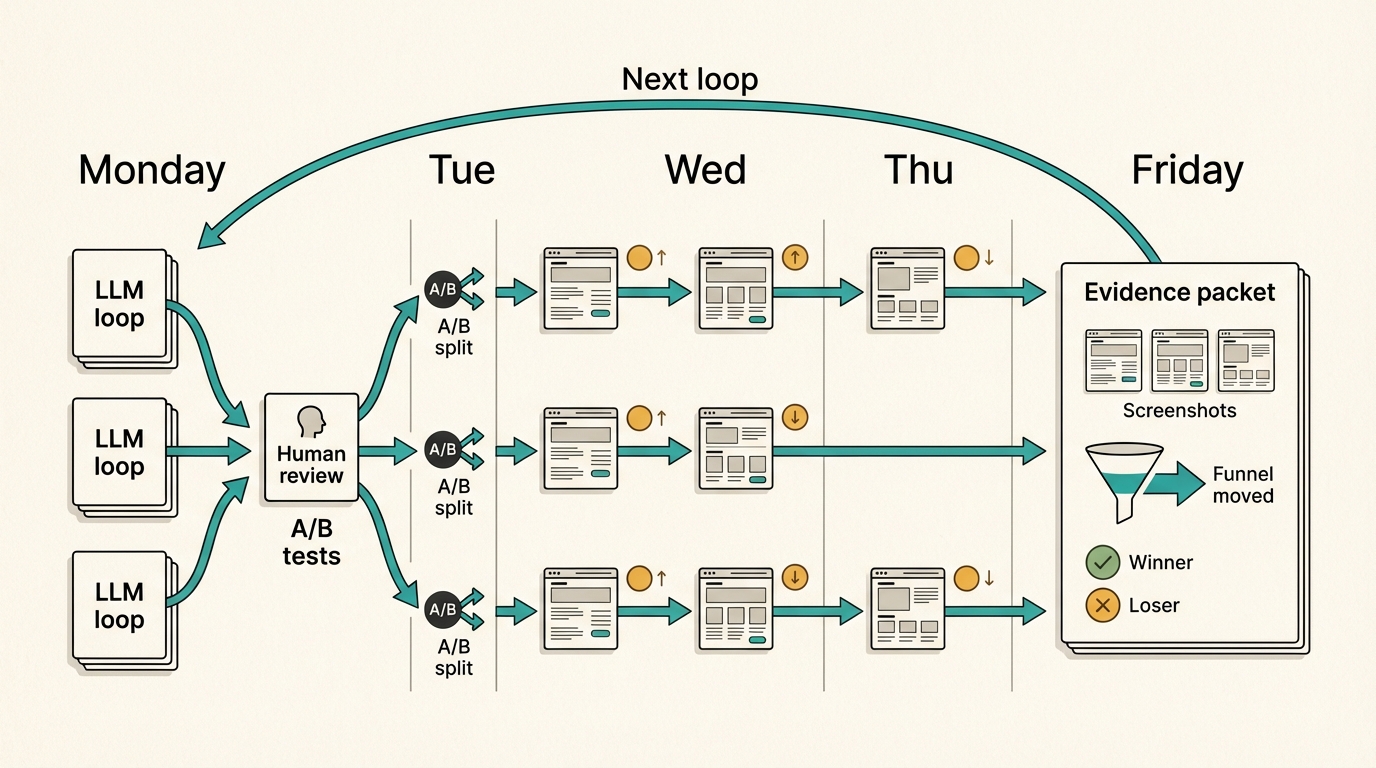
The inner loop is the LLM work:
- Run the autoresearch loop.
- Produce two distinct variants.
The outer loop is the growth system:
- Let a human review the product truth and risk.
- Ship the variants as an experiment.
- Wait for real behavior.
- Pull the result back into the next brief.
- Run the inner loop again from evidence.
That waiting period is not a bug.
It is the reality check.
At small scale, maybe you wait 24 or 48 hours. At bigger scale, you can run several experiments in parallel and review the week as a batch.
Tools like OpenClaw or Paperclip make that easier to manage because the work can live as assigned agent jobs, not another dashboard chore.
That is the future I care about: the agent comes back Friday with seven attempts, seven results, screenshots of what changed, funnel movement, what won, what lost, and what the next loop should try.
Not “here are more clever headlines.”
Evidence.
Where Agent Analytics Fits
This should work with any analytics data.
Agent Analytics makes the longer loop easier to manage because the same code agent can own the whole evidence loop:
- implement the approved variant on the landing page
- create the experiment
- run the experiment
- measure the experiment
- collect the previous experiment data into the next snapshot
- preserve the run history
- come back with evidence instead of another opinion
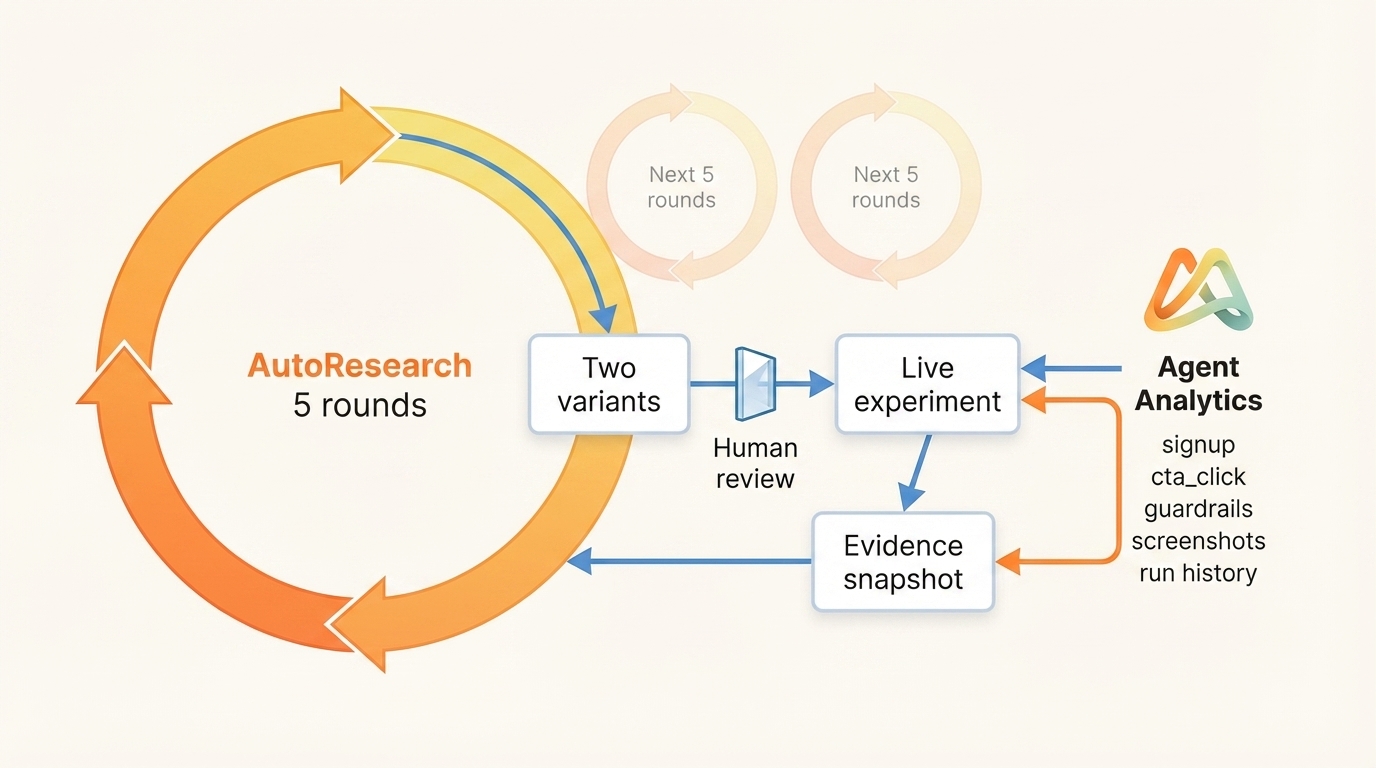
That is the value play:
agents propose
humans approve
experiments run
users decide
agents return with evidenceWhat We Built
program.mdtells the agent how to run the loop.brief.mddefines product truth, control copy, metrics, data, and drift constraints.results.tsvlogs each round.final_variants.mdstores the two winners for review.
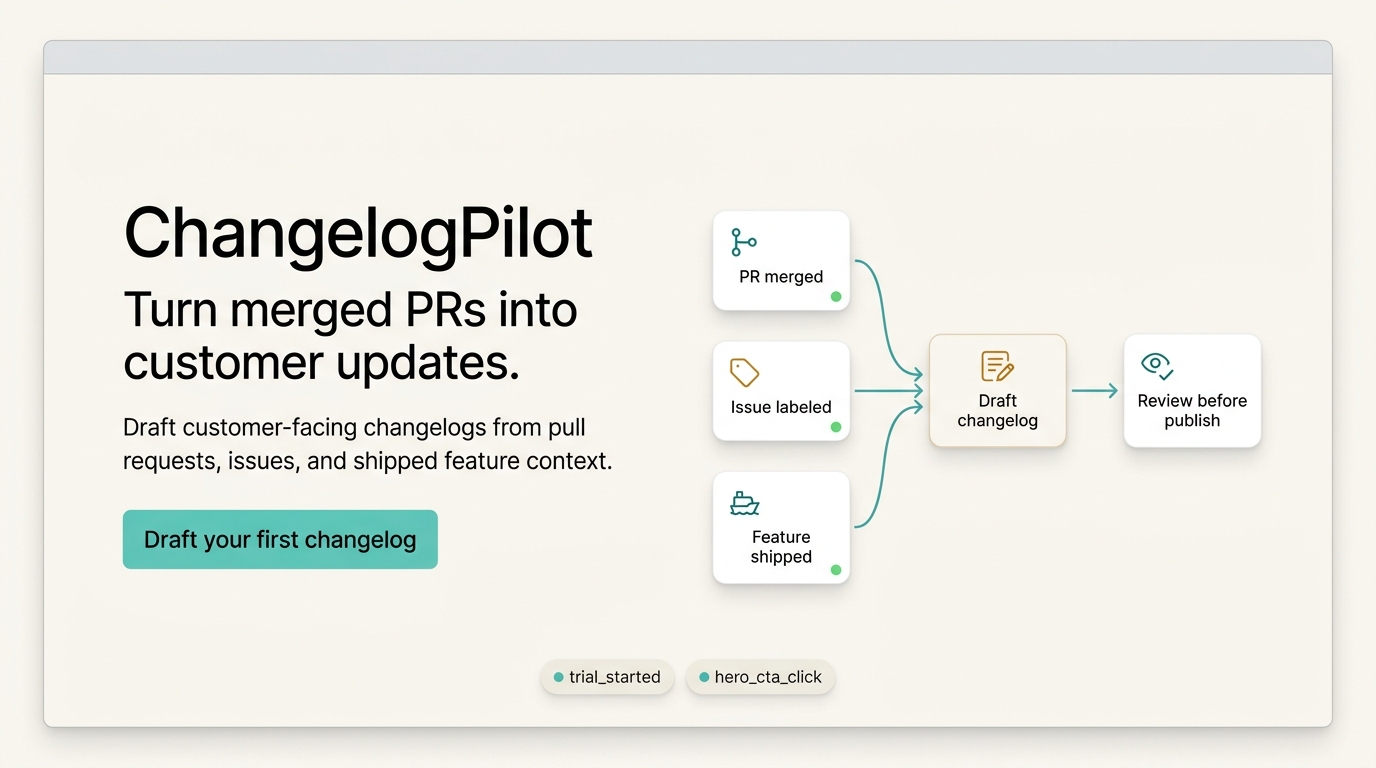
The repo also includes demo, ChangelogPilot (fake SaaS), see it working it without private data.
Try It
Start with the public GitHub repo: github.com/Agent-Analytics/autoresearch-growth
The sample demo does not require an Agent Analytics account, and it does not require the skill. Clone the repo, use the fake ChangelogPilot data, and ask your coding agent to run program.md. That gives you the full loop: brief, sample analytics snapshot, round log, Borda judging, and two final variants.
If you want the same workflow available as an agent skill:
npx skills add agent-analytics/skillsThen ask for the review-only loop:
Use the Agent Analytics Autoresearch skill.
Optimize the homepage hero for signup.
Use cta_click as the proxy metric.
Use recent experiment data when available.
Fetch the last 7 days, or whatever window makes sense.
Summarize what is useful and what is too sparse to trust.
Run 5 rounds.
Write final_variants.md with two variants for review.The skill treats implementation as a separate human-approved phase. After you approve a variant, the same agent can continue the outer loop:
Use the approved variants in final_variants.md.
Implement the homepage experiment.
Use the current page as the control, then test the two approved candidates against it.
Measure signup as the goal and cta_click as the proxy.
After the experiment window, collect results into the next data snapshot.
Start the next autoresearch loop from measured evidence.The point is not to replace human judgment.
The point is to make judgment compound.
LLMs can generate and criticize. Humans can approve the risk. Users decide what worked. The next loop should start there.


